
Mitt første møte med et åpnere bibliotek var på slutten av åttitallet, da NTUB jekket ned skranken i hovedbiblioteket. Like etterpå kom internettet, og begrepet åpenhet har tatt en ny vending etter det.

Den gamle skranken ved NTUB, her med Bjørg og Per. Foto Nils Bjørnelv
Åpenhet er bra. Det kan bety at biblioteket er lett tilgjengelig, at det finnes overalt, at åpningstidene er ok, at det er innbydende osv osv. Her vil jeg imidlertid se spesielt på åpenhet i et IT-perspektiv, og det blir vel som vanlig i denne bloggen med spesiell fokus på fagbibliotekene.
Åpen kildekode
Dette er en egenskap ved datasystemer som ikke nødvendigvis betinger at de er gratis, men at kildekoden er tilgjengelig slik at vi (bibliotekene) kan utnytte dette til å sjøl gjøre endringer. Her er det også en vanlig forutsetning at slike endringer som blir gjort av andre enn den opprinnelige opphavsinstansen kan bli «pløyd tilbake», og dermed komme andre brukere til gode. Dette er slett ikke vanlige betingelser for våre datasystemer.
Åpen publisering
På engelsk heter det Open Access, og her er det nok en forutsetning at publikasjonene er fritt og gratis tilgjengelige. Det er sjølsagt et mysterium for de fleste at forskningsresultater som har framkommet med offentlige midler, feks her i universitetene, blir publisert på en slik måte at til og med de samme institusjonene (ja i verste fall til og med forfatterne) må kjøpe dem tilbake.
Det kan diskuteres hvem som er pådrivere og hvem som er bremser i prosessen for et åpnere publiseringssystem. Bibliotekene bør gå fremst i dette toget.
Åpne IT-systemer
Åpenhet angår mye mer enn selve kildekoden. Vi ønsker gjerne å ha IT-systemer som er: Bransjeuavhengige, leverandøruavhengige, utskiftbare, flyttbare, skalerbare, dokumenterte osv. Alt dette er egenskaper som etter mitt syn har med åpenhet å gjøre.
Dette kan gjerne sammenfattes i utsagnet «Det er bedre med 10 skruer løs enn en som har rustet fast». Det er nok en kjensgjerning at en del av våre kjernesystemer ifølge disse kriteriene er langt fra åpne.
Å vise vei i stedet for å stå i veien.
Nei dette er ikke et sitat fra Kjartan Fløgstad :-). Det er grunn til å legge merke til at brukere av og til betrakter biblioteket som en omvei, som driver med sin mer eller mindre esoteriske virksomhet vha interne systemer og et hemmelig språk og en stadig masing om å lære opp brukerne i det faget som heter informasjonskompetanse. Urettferdig? Tja, ikke sikkert det. I alle fall har dette etter mitt syn noe med åpenhet å gjøre. Og – i alle fall – vi må etterstrebe å snakke et vanlig språk. Av og til synes jeg at vi (bibliotekene) oppfører oss som om vi er litt skamfulle for at det ikke var vi som fant opp nettet, og derfor må vi kompensere ved i det minste beholde vårt eget snevre fagspråk. Det er ikke særlig lurt!
Standarder
Når systemene skal samarbeide, er det gjerne mye snakk om hvilke standarder man skal bruke for å lage grenseenitt. Å komme fram til den ene «sanne standarden» har vært en målsetting som ikke nødvendigvis har vært gunstig. Det kan kanskje heller være lurt å forholde seg til en virkelighet hvor informasjon, data, systemer og tjenester ikke følger vår foretrukne ISO-standard, fordi den (altså standarden) framstår som uferdig, uforståelig og utilgjengelig. Å la de hundre blomster blomstre er en strategi som bør få mer oppmerksomhet, kanskje kan den sammen med darwinistiske mekanismer oppnå mer enn smalsporet standard-tenking.
En helt spesiell egenskap ved standarder er at de ofte inneholder detaljerte semantiske beskrivelser av data. Slik at den som skal bruke dataene har bruk for å kunne standarden. En alternativ og trolig mer robust måte er å gjøre semantikken eksplisitt, en del av dataene, slik som feks er et grunnleggende prinsipp i RDF og linked data.
Rådata
En form for åpenhet består i å gi brukerne tilgang til rådata, ikke bare til ferdigkokte dokumenter. Dette tillater å tilberede (behandle) dataene med andre hypoteser og andre verktøy, eller kanskje overprøve resultater som presenteres i dokumentene.
Innenfra og ut
En form for lukkethet er når institusjonene bruker sine «bokbudsjetter» på å skaffe «sine brukere» (studenter og ansatte) tilgang til forskningsdata produsert ved andre institusjoner gjennom rådyre mellomledd (betalingsmurer). Enn om alle sammen i stedet fokuserte på å gjøre sine egne data så tilgjengelig som mulig for andre? Altså «innenfra og ut» i stedet for «utenfra og inn».
Idet jeg i skrivende stund er i ferd med å forlate NTNU, så mister jeg samtidig tilgang til alle de dataene og alle den informasjon som NTNU kjøper. Det gjelder ikke bare pensjonisten, men enhver som forlater NTNU, f.eks. en ferdiguteksaminert student. Det er kanskje rettferdig. Eller kanskje ikke?
OK
dette bildet passer ikke ditt bibliotek? Nei, kanskje ikke hvis det er et folkebibliotek. Men kanskje likevel til en viss grad? I alle fall. Jeg tror at parolen «Et åpnere bibliotek» alltid har sin misjon.



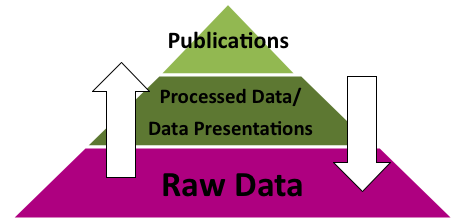
 Jeg kan jo prøve, med utgangspunkt i denne trekanten som vel de fleste har sett, å si at Informasjon er kodet i form av data, og kan brukes for å gi kunnskap – eller noe sånt. Og så har jeg hatt følelsen av at innen biblioteket så arbeider vi mest i midtsjiktet, dvs med informasjon. Det som er «varen» hos oss er bøker, artikler, rapporter, bilder, manuskripter, lyd, levende bilder, noter, kart &c &c. Vi er vant til å kalle alt dette for dokumenter (sjøl om vi for ca 15 år siden prøvde vi oss fram med mer moderne termer som dokumentlignende objekter (grøss) og informasjonsobjekter).
Jeg kan jo prøve, med utgangspunkt i denne trekanten som vel de fleste har sett, å si at Informasjon er kodet i form av data, og kan brukes for å gi kunnskap – eller noe sånt. Og så har jeg hatt følelsen av at innen biblioteket så arbeider vi mest i midtsjiktet, dvs med informasjon. Det som er «varen» hos oss er bøker, artikler, rapporter, bilder, manuskripter, lyd, levende bilder, noter, kart &c &c. Vi er vant til å kalle alt dette for dokumenter (sjøl om vi for ca 15 år siden prøvde vi oss fram med mer moderne termer som dokumentlignende objekter (grøss) og informasjonsobjekter).


{kind=link}